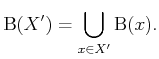Next: Further Reading Up: 8.5.2 Dynamic Programming with Previous: Topological considerations
For motion planning problems, it is expected that
![]() ,
as computed from (8.62), is always close to
,
as computed from (8.62), is always close to ![]() relative to the size of
relative to the size of ![]() . This suggests the use of a Dijkstra-like
algorithm to compute optimal feedback plans more efficiently. As
discussed for the finite case in Section 2.3.3, many values
remain unchanged during the value iterations, as indicated in Example
2.5. Dijkstra's algorithm maintains a data
structure that focuses the computation on the part of the state space
where values are changing. The same can be done for the continuous
case by carefully considering the sample points [607].
. This suggests the use of a Dijkstra-like
algorithm to compute optimal feedback plans more efficiently. As
discussed for the finite case in Section 2.3.3, many values
remain unchanged during the value iterations, as indicated in Example
2.5. Dijkstra's algorithm maintains a data
structure that focuses the computation on the part of the state space
where values are changing. The same can be done for the continuous
case by carefully considering the sample points [607].
During the value iterations, there are three kinds of sample points, just as in the discrete case (recall from Section 2.3.3):
Imagine the first value iteration. Initially, all points in ![]() are
set to zero values. Among the collection of samples
are
set to zero values. Among the collection of samples ![]() , how many
can reach
, how many
can reach ![]() in a single stage? We expect that samples very far
from
in a single stage? We expect that samples very far
from ![]() will not be able to reach
will not be able to reach ![]() ; this keeps their values are
infinity. The samples that are close to
; this keeps their values are
infinity. The samples that are close to ![]() should reach it. It
would be convenient to prune away from consideration all samples that
are too far from
should reach it. It
would be convenient to prune away from consideration all samples that
are too far from ![]() to lower their value. In every iteration, we
eliminate iterating over samples that are too far away from those
already reached. It is also unnecessary to iterate over the dead
samples because their values no longer change.
to lower their value. In every iteration, we
eliminate iterating over samples that are too far away from those
already reached. It is also unnecessary to iterate over the dead
samples because their values no longer change.
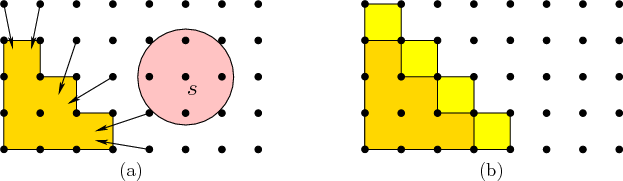
To keep track of reachable samples, it will be convenient to introduce
the notion of a backprojection, which will be studied further in
Section 10.1. For a single state, ![]() , its
backprojection is defined as
, its
backprojection is defined as
Now consider a version of value iteration that uses backprojections to
eliminate some states from consideration because it is known that
their values cannot change. Let ![]() refer to the number of stages
considered by the current value iteration. During the first
iteration,
refer to the number of stages
considered by the current value iteration. During the first
iteration, ![]() , which means that all one-stage trajectories are
considered. Let
, which means that all one-stage trajectories are
considered. Let ![]() be the set of samples (assuming already that none
lie in
be the set of samples (assuming already that none
lie in
![]() ). Let
). Let ![]() and
and ![]() refer to the dead and alive samples,
respectively. Initially,
refer to the dead and alive samples,
respectively. Initially, ![]() , the set of samples in the goal
set. The first set,
, the set of samples in the goal
set. The first set, ![]() , of alive samples is assigned by using the
concept of a frontier. The frontier of a
set
, of alive samples is assigned by using the
concept of a frontier. The frontier of a
set
![]() of sample points is
of sample points is
 |
Now the approach is described for iteration ![]() . The
cost-to-go update (8.56) is computed at all points
in
. The
cost-to-go update (8.56) is computed at all points
in ![]() . If
. If
![]() for some
for some ![]() , then
, then
![]() is declared dead and moved to
is declared dead and moved to ![]() . Samples are never
removed from the dead set; therefore, all points in
. Samples are never
removed from the dead set; therefore, all points in ![]() are also
added to
are also
added to ![]() . The next active set,
. The next active set, ![]() , includes all
samples in
, includes all
samples in ![]() , excluding those that were moved to the dead set.
Furthermore, all samples in
, excluding those that were moved to the dead set.
Furthermore, all samples in
![]() are added to
are added to ![]() because these will produce a finite cost-to-go value in the next
iteration. The iterations continue as usual until some stage,
because these will produce a finite cost-to-go value in the next
iteration. The iterations continue as usual until some stage, ![]() , is
reached for which
, is
reached for which ![]() is empty, and
is empty, and ![]() includes all samples from
which the goal can be reached (under the approximation assumptions
made in this section).
includes all samples from
which the goal can be reached (under the approximation assumptions
made in this section).
For efficiency purposes, an approximation to
![]() may be used,
provided that the true frontier is a proper subset of the approximate
frontier. For example, the frontier might add all new samples within
a specified radius of points in
may be used,
provided that the true frontier is a proper subset of the approximate
frontier. For example, the frontier might add all new samples within
a specified radius of points in ![]() . In this case, the updated
cost-to-go value for some
. In this case, the updated
cost-to-go value for some ![]() may remain infinite. If this
occurs, it is of course not added to
may remain infinite. If this
occurs, it is of course not added to ![]() . Furthermore, it is
deleted from
. Furthermore, it is
deleted from ![]() in the computation of the next frontier (the
frontier should only be computed for samples that have finite
cost-to-go values).
in the computation of the next frontier (the
frontier should only be computed for samples that have finite
cost-to-go values).
The approach considered so far can be expected to reduce the amount of
computations in each value iteration by eliminating the evaluation of
(8.56) on unnecessary samples. The same cost-to-go
values are obtained in each iteration because only samples for which
the value cannot change are eliminated in each iteration. The
resulting algorithm still does not, however, resemble Dijkstra's
algorithm because value iterations are performed over all of ![]() in
each stage.
in
each stage.
To make a version that behaves like Dijkstra's algorithm, a
queue ![]() will be introduced. The algorithm removes the smallest
element of
will be introduced. The algorithm removes the smallest
element of ![]() in each iteration. The interpolation version first
assigns
in each iteration. The interpolation version first
assigns
![]() for each
for each ![]() . It also maintains a set
. It also maintains a set
![]() of dead samples, which is initialized to
of dead samples, which is initialized to ![]() . For each
. For each
![]() , the cost-to-go update (8.56) is
computed. The priority
, the cost-to-go update (8.56) is
computed. The priority ![]() is initialized to
is initialized to
![]() , and
elements are sorted by their current cost-to-go values (which may not
be optimal). The algorithm iteratively removes the smallest element
from
, and
elements are sorted by their current cost-to-go values (which may not
be optimal). The algorithm iteratively removes the smallest element
from ![]() (because its optimal cost-to-go is known to be the current
value) and terminates when
(because its optimal cost-to-go is known to be the current
value) and terminates when ![]() is empty. Each time the smallest
element,
is empty. Each time the smallest
element, ![]() , is removed, it is inserted into
, is removed, it is inserted into ![]() . Two
procedures are then performed: 1) Some elements in the queue need to
have their cost-to-go values recomputed using (8.56)
because the value
. Two
procedures are then performed: 1) Some elements in the queue need to
have their cost-to-go values recomputed using (8.56)
because the value ![]() is known to be optimal, and their
values may depend on it. These are the samples in
is known to be optimal, and their
values may depend on it. These are the samples in ![]() that lie in
that lie in
![]() (in which
(in which ![]() just got extended to include
just got extended to include ![]() ). 2) Any
samples in
). 2) Any
samples in
![]() that are not in
that are not in ![]() are inserted into
are inserted into ![]() after computing their cost-to-go values using (8.56).
This enables the active set of samples to grow as the set of dead
samples grows. Dijkstra's algorithm with interpolation does not
compute values that are identical to those produced by value
iterations because
after computing their cost-to-go values using (8.56).
This enables the active set of samples to grow as the set of dead
samples grows. Dijkstra's algorithm with interpolation does not
compute values that are identical to those produced by value
iterations because ![]() is not explicitly stored when
is not explicitly stored when
![]() is computed. Each computed value is some cost-to-go,
but it is only known to be the optimal when the sample is placed into
is computed. Each computed value is some cost-to-go,
but it is only known to be the optimal when the sample is placed into
![]() . It can be shown, however, that the method converges because
computed values are no higher than what would have been computed in a
value iteration. This is also the basis of dynamic programming using
Gauss-Seidel iterations [96].
. It can be shown, however, that the method converges because
computed values are no higher than what would have been computed in a
value iteration. This is also the basis of dynamic programming using
Gauss-Seidel iterations [96].
A specialized, wavefront-propagation
version of the algorithm can be made for the special case of finding
solutions that reach the goal in the smallest number of stages. The
algorithm is similar to the one shown in Figure 8.4.
It starts with an initial wavefront ![]() in which
in which
![]() for each
for each ![]() . In each iteration, the optimal cost-to-go
value
. In each iteration, the optimal cost-to-go
value ![]() is increased by one, and the wavefront,
is increased by one, and the wavefront, ![]() , is
computed from
, is
computed from ![]() as
as
![]() . The algorithm
terminates at the first iteration in which the wavefront is empty.
. The algorithm
terminates at the first iteration in which the wavefront is empty.
Steven M LaValle 2012-04-20