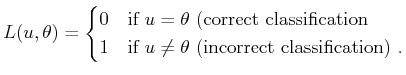Next: A Bayesian classifier Up: 9.2.4 Examples of Optimal Previous: 9.2.4 Examples of Optimal
An active field over the past several decades in computer vision and machine learning has been pattern classification [271,295,711]. The general problem involves using a set of data to perform classifications. For example, in computer vision, the data correspond to information extracted from an image. These indicate observed features of an object that are used by a vision system to try to classify the object (e.g., ``I am looking at a bowl of Vietnamese noodle soup'').
The presentation here represents a highly idealized version of pattern classification. We will assume that all of the appropriate model details, including the required probability distributions, are available. In some contexts, these can be obtained by gathering statistics over large data sets. In many applications, however, obtaining such data is expensive or inaccessible, and classification techniques must be developed in lieu of good information. Some problems are even unsupervised, which means that the set of possible classes must also be discovered automatically. Due to issues such as these, pattern classification remains a challenging research field.
The general model is that nature first determines the class, then
observations are obtained regarding the class, and finally the robot
action attempts to guess the correct class based on the observations.
The problem fits under Formulation 9.5. Let ![]() denote a finite set of classes. Since the robot must guess the
class,
denote a finite set of classes. Since the robot must guess the
class,
![]() . A simple cost function is defined to measure the
mismatch between
. A simple cost function is defined to measure the
mismatch between ![]() and
and ![]() :
:
The next part of the formulation considers information that is used to
make the classification decision. Let ![]() denote a feature
space, in which each
denote a feature
space, in which each ![]() is called a feature or
feature vector (often
is called a feature or
feature vector (often
![]() ). The feature in this
context is just an observation, as given in Formulation
9.5. The best classifier or classification
rule is a strategy
). The feature in this
context is just an observation, as given in Formulation
9.5. The best classifier or classification
rule is a strategy
![]() that provides the smallest
classification error in the worst case or expected case, depending on
the model.
that provides the smallest
classification error in the worst case or expected case, depending on
the model.