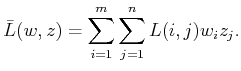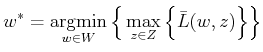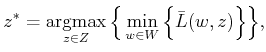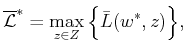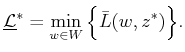Next: 9.3.3.2 Computation of randomized Up: 9.3.3 Randomized Strategies Previous: 9.3.3 Randomized Strategies
Since a game under Formulation 9.7 can be nicely
expressed as a matrix, it is tempting to use linear algebra to
conveniently express expected costs. Let ![]() and
and ![]() . As
in Section 9.1.3, a randomized strategy for
. As
in Section 9.1.3, a randomized strategy for
![]() can be
represented as an
can be
represented as an ![]() -dimensional vector,
-dimensional vector,
| (9.55) |
Let
![]() denote the expected cost that will be received if
denote the expected cost that will be received if
![]() plays
plays ![]() and
and
![]() plays
plays ![]() . This can be computed as
. This can be computed as
Let ![]() and
and ![]() denote the set of all randomized strategies for
denote the set of all randomized strategies for
![]() and
and
![]() , respectively. These spaces include strategies that are
equivalent to the deterministic strategies considered in Section
9.3.2 by assigning probability one to a single action.
Thus,
, respectively. These spaces include strategies that are
equivalent to the deterministic strategies considered in Section
9.3.2 by assigning probability one to a single action.
Thus, ![]() and
and ![]() can be considered as expansions of the set of
possible strategies in comparison to what was available in the
deterministic setting. Using
can be considered as expansions of the set of
possible strategies in comparison to what was available in the
deterministic setting. Using ![]() and
and ![]() , randomized security
strategies for
, randomized security
strategies for
![]() and
and
![]() are defined as
are defined as
The randomized upper value is defined as
The most fundamental result in zero-sum game theory was shown by von
Neumann [956,957], and it states that
![]() for any game in Formulation 9.7. This yields
the randomized value
for any game in Formulation 9.7. This yields
the randomized value
![]() for the game. This means that there
will never be expected regret if the players stay with their security
strategies. If the players apply their randomized security
strategies, then a randomized saddle point is obtained. This
saddle point cannot be seen as a simple pattern in the matrix
for the game. This means that there
will never be expected regret if the players stay with their security
strategies. If the players apply their randomized security
strategies, then a randomized saddle point is obtained. This
saddle point cannot be seen as a simple pattern in the matrix ![]() because it instead exists over
because it instead exists over ![]() and
and ![]() .
.
The guaranteed existence of a randomized saddle point is an important result because it demonstrates the value of randomization when making decisions against an intelligent opponent. In Example 9.7, it was intuitively argued that randomization seems to help when playing against an intelligent adversary. When playing the game repeatedly with a deterministic strategy, the other player could learn the strategy and win every time. Once a randomized strategy is used, the players will not experience regret.