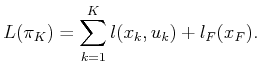Next: 2.3.1 Optimal Fixed-Length Plans Up: 2. Discrete Planning Previous: 2.2.4 A Unified View
This section extends Formulation 2.1 to allow optimal planning problems to be defined. Rather than being satisfied with any sequence of actions that leads to the goal set, suppose we would like a solution that optimizes some criterion, such as time, distance, or energy consumed. Three important extensions will be made: 1) A stage index will be used to conveniently indicate the current plan step; 2) a cost functional will be introduced, which behaves like a taxi meter by indicating how much cost accumulates during the plan execution; and 3) a termination action will be introduced, which intuitively indicates when it is time to stop the plan and fix the total cost.
The presentation involves three phases. First, the problem of finding optimal paths of a fixed length is covered in Section 2.3.1. The approach, called value iteration, involves iteratively computing optimal cost-to-go functions over the state space. Although this case is not very useful by itself, it is much easier to understand than the general case of variable-length plans. Once the concepts from this section are understood, their extension to variable-length plans will be much clearer and is covered in Section 2.3.2. Finally, Section 2.3.3 explains the close relationship between value iteration and Dijkstra's algorithm, which was covered in Section 2.2.1.
With nearly all optimization problems, there is the arbitrary,
symmetric choice of whether to define a criterion to minimize or
maximize. If the cost is a kind of energy or expense, then
minimization seems sensible, as is typical in robotics and control
theory. If the cost is a kind of reward, as in investment planning or
in most AI books, then maximization is preferred. Although this issue
remains throughout the book, we will choose to minimize everything.
If maximization is instead preferred, then multiplying the costs by
![]() and swapping minimizations with maximizations should suffice.
and swapping minimizations with maximizations should suffice.
The fixed-length optimal planning formulation will be given shortly,
but first we introduce some new notation. Let ![]() denote a
denote a ![]() -step plan, which is a sequence
-step plan, which is a sequence ![]() ,
, ![]() ,
, ![]() ,
, ![]() of
of
![]() actions. If
actions. If ![]() and
and ![]() are given, then a sequence of
states,
are given, then a sequence of
states, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , can be derived using the
state transition function,
, can be derived using the
state transition function, ![]() . Initially,
. Initially,
![]() , and each
subsequent state is obtained by
, and each
subsequent state is obtained by
![]() .
.
The model is now given; the most important addition with respect to
Formulation 2.1 is ![]() , the cost functional.
, the cost functional.
An important comment must be made regarding ![]() . Including
. Including ![]() in
(2.4) is actually unnecessary if it is agreed in advance
that
in
(2.4) is actually unnecessary if it is agreed in advance
that ![]() will only be applied to evaluate plans that reach
will only be applied to evaluate plans that reach ![]() .
It would then be undefined for all other plans. The algorithms to be
presented shortly will also function nicely under this assumption;
however, the notation and explanation can become more cumbersome
because the action space must always be restricted to ensure that
successful plans are produced. Instead of this, the domain of
.
It would then be undefined for all other plans. The algorithms to be
presented shortly will also function nicely under this assumption;
however, the notation and explanation can become more cumbersome
because the action space must always be restricted to ensure that
successful plans are produced. Instead of this, the domain of ![]() is
extended to include all plans, and those that do not reach
is
extended to include all plans, and those that do not reach ![]() are penalized with infinite cost so that they are eliminated
automatically in any optimization steps. At some point, the role of
are penalized with infinite cost so that they are eliminated
automatically in any optimization steps. At some point, the role of
![]() may become confusing, and it is helpful to remember that it is
just a trick to convert feasibility constraints into a straightforward
optimization (
may become confusing, and it is helpful to remember that it is
just a trick to convert feasibility constraints into a straightforward
optimization (
![]() means not feasible and
means not feasible and
![]() means feasible with cost
means feasible with cost ![]() ).
).
Now the task is to find a plan that minimizes ![]() . To obtain a
feasible planning problem like Formulation 2.1 but
restricted to
. To obtain a
feasible planning problem like Formulation 2.1 but
restricted to ![]() -step plans, let
-step plans, let
![]() . To obtain a
planning problem that requires minimizing the number of stages, let
. To obtain a
planning problem that requires minimizing the number of stages, let
![]() . The possibility also exists of having goals that
are less ``crisp'' by letting
. The possibility also exists of having goals that
are less ``crisp'' by letting ![]() vary for different
vary for different
![]() , as opposed to
, as opposed to
![]() . This is much more general than
what was allowed with feasible planning because now states may take on
any value, as opposed to being classified as inside or outside of
. This is much more general than
what was allowed with feasible planning because now states may take on
any value, as opposed to being classified as inside or outside of
![]() .
.