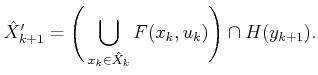Next: Moment-based approximations Up: 11.4.3.2 Approximating nondeterministic and Previous: 11.4.3.2 Approximating nondeterministic and
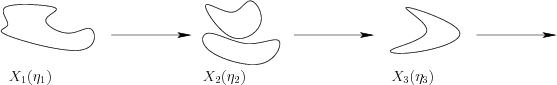 |
Suppose that nondeterministic uncertainty is used and an approximation
is made to the nondeterministic I-states. An I-map,
![]() , will be defined in which
, will be defined in which
![]() is a
particular family of subsets of
is a
particular family of subsets of ![]() . For example,
. For example,
![]() could
represent the set of all ball subsets of
could
represent the set of all ball subsets of ![]() . If
. If
![]() , then
the balls become discs, and only three parameters
, then
the balls become discs, and only three parameters ![]() are needed
to parameterize
are needed
to parameterize
![]() (
(![]() for the center and
for the center and ![]() for the
radius). This implies that
for the
radius). This implies that
![]() ; this appears to
be much simpler than
; this appears to
be much simpler than
![]() , which could be a complicated
collection of regions in
, which could be a complicated
collection of regions in
![]() . To make
. To make
![]() even smaller, it
could be required that
even smaller, it
could be required that ![]() ,
, ![]() , and
, and ![]() are integers (or are sampled
with some specified dispersion, as defined in Section
5.2.3). If
are integers (or are sampled
with some specified dispersion, as defined in Section
5.2.3). If
![]() is bounded, then the number of
derived I-states would become finite. Of course, this comes an at
expense because
is bounded, then the number of
derived I-states would become finite. Of course, this comes an at
expense because
![]() may be poorly approximated.
may be poorly approximated.
For a fixed sequence of actions (![]() ,
, ![]() ,
, ![]() ) consider
the sequence of nondeterministic I-states:
) consider
the sequence of nondeterministic I-states:
| (11.59) |
If it is difficult to compute
![]() , one possibility is to try
to define a derived information transition equation, as discussed in
Section 11.2.1. The trouble, however, is that
, one possibility is to try
to define a derived information transition equation, as discussed in
Section 11.2.1. The trouble, however, is that
![]() is
usually not a sufficient I-map. Imagine wanting to compute
is
usually not a sufficient I-map. Imagine wanting to compute
![]() , which is a bounding approximation to
, which is a bounding approximation to
![]() . This can be accomplished by starting with
. This can be accomplished by starting with
![]() , applying the update rules (11.30) and
(11.31), and then applying
, applying the update rules (11.30) and
(11.31), and then applying
![]() to
to
![]() . In general, this does not produce the same
result as starting with the bounding volume
. In general, this does not produce the same
result as starting with the bounding volume
![]() ,
applying (11.30) and (11.31), and then
applying
,
applying (11.30) and (11.31), and then
applying
![]() .
.
Thus, it is not possible to express the transitions entirely in
![]() without some further loss of information. However, if this
loss of information is tolerable, then an information-destroying
approximation may nevertheless be useful. The general idea is to make
a bounding region for the nondeterministic I-state in each iteration.
Let
without some further loss of information. However, if this
loss of information is tolerable, then an information-destroying
approximation may nevertheless be useful. The general idea is to make
a bounding region for the nondeterministic I-state in each iteration.
Let
![]() denote this bounding region at stage
denote this bounding region at stage ![]() . Be careful
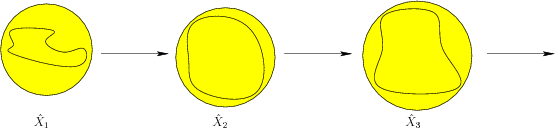
in using such approximations. As depicted in Figures
11.9 and 11.10, the sequences of
derived I-states diverge. The sequence in Figure 11.10
is not obtained by simply bounding each calculated I-state by an
element of
. Be careful
in using such approximations. As depicted in Figures
11.9 and 11.10, the sequences of
derived I-states diverge. The sequence in Figure 11.10
is not obtained by simply bounding each calculated I-state by an
element of
![]() ; the entire sequence is different.
; the entire sequence is different.
Initially,
![]() is chosen so that
is chosen so that
![]() . In each inductive step,
. In each inductive step,
![]() is treated as if it
were the true nondeterministic I-state (not an approximation). Using
(11.30) and (11.31), the update for
considering
is treated as if it
were the true nondeterministic I-state (not an approximation). Using
(11.30) and (11.31), the update for
considering ![]() and
and ![]() is
is
| (11.61) |
Both a plan,
![]() , and information
transitions can now be defined over
, and information
transitions can now be defined over
![]() . To ensure that a plan
is sound, the approximation must be conservative. If in some
iteration,
. To ensure that a plan
is sound, the approximation must be conservative. If in some
iteration,
![]() , then the true state may not
necessarily be included in the approximate derived I-state. This
could, for example, mean that a robot is in a collision state, even
though the derived I-state indicates that this is impossible. This
bad behavior is generally avoided by keeping conservative
approximations. At one extreme, the approximations can be made very
conservative by always assigning
, then the true state may not
necessarily be included in the approximate derived I-state. This
could, for example, mean that a robot is in a collision state, even
though the derived I-state indicates that this is impossible. This
bad behavior is generally avoided by keeping conservative
approximations. At one extreme, the approximations can be made very
conservative by always assigning
![]() .
This, however, is useless because the only possible plans must apply a
single, fixed action for every stage. Even if the approximations are
better, it might still be impossible to cause transitions in the
approximated I-state. To ensure that solutions exist to the planning
problem, it is therefore important to make the bounding volumes as
close as possible to the derived I-states.
.
This, however, is useless because the only possible plans must apply a
single, fixed action for every stage. Even if the approximations are
better, it might still be impossible to cause transitions in the
approximated I-state. To ensure that solutions exist to the planning
problem, it is therefore important to make the bounding volumes as
close as possible to the derived I-states.
This trade-off between the simplicity of bounding volumes and the
computational expense of working with them was also observed in
Section 5.3.2 for collision detection. Dramatic
improvement in performance can be obtained by working with simpler
shapes; however, in the present context this could come at the expense
of failing to solve the problem. Using balls as described so far
might not seem to provide very tight bounds. Imagine instead using
solid ellipsoids. This would provide tighter approximations, but the
dimension of
![]() grows quadratically with the dimension of
grows quadratically with the dimension of ![]() .
A sphere equation generally requires
.
A sphere equation generally requires ![]() parameters, whereas the
ellipsoid equation requires
parameters, whereas the
ellipsoid equation requires
![]() parameters. Thus, if
the dimension of
parameters. Thus, if
the dimension of ![]() is high, it may be difficult or even impossible
to use ellipsoid approximations. Nonconvex bounding shapes could
provide even better approximations, but the required number of
parameters could easily become unmanageable, even if
is high, it may be difficult or even impossible
to use ellipsoid approximations. Nonconvex bounding shapes could
provide even better approximations, but the required number of
parameters could easily become unmanageable, even if
![]() . For
very particular problems, however, it may be possible to design a
family of shapes that is both manageable and tightly approximates the
nondeterministic I-states. This leads to many interesting research
issues.
. For
very particular problems, however, it may be possible to design a
family of shapes that is both manageable and tightly approximates the
nondeterministic I-states. This leads to many interesting research
issues.
Steven M LaValle 2012-04-20