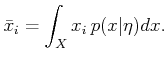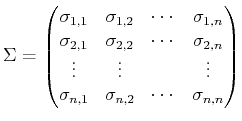Next: 11.4.3.3 Derived I-spaces for Up: 11.4.3.2 Approximating nondeterministic and Previous: Conservative approximations
Since the probabilistic I-states are functions, it seems natural to
use function approximation methods to approximate
![]() . One
possibility might be to use the first
. One
possibility might be to use the first ![]() coefficients of a Taylor
series expansion. The derived I-space then becomes the space of
possible Taylor coefficients. The quality of the approximation is
improved as
coefficients of a Taylor
series expansion. The derived I-space then becomes the space of
possible Taylor coefficients. The quality of the approximation is
improved as ![]() is increased, but also the dimension of the derived
I-space rises.
is increased, but also the dimension of the derived
I-space rises.
Since we are working with probability density functions, it is
generally preferable to use moments as approximations instead of
Taylor series coefficients or other generic function approximation
methods. The first and second moments are the familiar mean and
covariance, respectively. These are preferable over other
approximations because the mean and covariance exactly represent the
Gaussian density, which is the most basic and fundamental density in
probability theory. Thus, approximating the probabilistic I-space
with first and second moments is equivalent to assuming that the
resulting probability densities are always Gaussian. Such
approximations are frequently made in practice because of the
convenience of working with Gaussians. In general, higher order
moments can be used to obtain higher quality approximations at the
expense of more coefficients. Let
![]() denote a moment-based I-map.
denote a moment-based I-map.
The same issues arise for
![]() as for
as for
![]() . In most
cases,
. In most
cases,
![]() is not a sufficient I-map. The moments are computed
in the same way as the conservative approximations. The update
equations (11.57) and (11.58) are
applied for probabilistic I-states; however, after each step,
is not a sufficient I-map. The moments are computed
in the same way as the conservative approximations. The update
equations (11.57) and (11.58) are
applied for probabilistic I-states; however, after each step,
![]() is applied to the resulting probability density function.
This traps the derived I-states in
is applied to the resulting probability density function.
This traps the derived I-states in
![]() . The moments could be
computed after each of (11.57) and
(11.58) or after both of them have been applied
(different results may be obtained). The later case may be more
difficult to compute, depending on the application.
. The moments could be
computed after each of (11.57) and
(11.58) or after both of them have been applied
(different results may be obtained). The later case may be more
difficult to compute, depending on the application.
First consider using the mean (first moment) to represent some
probabilistic I-state,
![]() . Let
. Let ![]() denote the
denote the ![]() th
coordinate of
th
coordinate of ![]() . The mean,
. The mean, ![]() , with respect to
, with respect to ![]() is
generally defined as
is
generally defined as
Using second moments helps to alleviate this problem. The covariance
with respect to two variables, ![]() and
and ![]() , is
, is
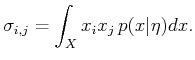 |
(11.63) |
Higher quality approximations can be made by taking higher order
moments. The ![]() th moment is defined
as
th moment is defined
as
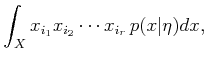 |
(11.65) |
The moment-based approximation is very similar to the conservative
approximations for nondeterministic uncertainty. The use of mean and
covariance appears very similar to using ellipsoids for the
nondeterministic case. The level sets of a Gaussian density are
ellipsoids. These level sets generalize the notion of confidence
intervals to confidence ellipsoids, which provides a close connection
between the nondeterministic and probabilistic cases. The domain of a
Gaussian density is
![]() , which is not bounded, contrary to the
nondeterministic case. However, for a given confidence level, it can
be approximated as a bounded set. For example, an elliptical region
can be computed in which
, which is not bounded, contrary to the
nondeterministic case. However, for a given confidence level, it can
be approximated as a bounded set. For example, an elliptical region
can be computed in which ![]() of the probability mass falls. In
general, it may be possible to combine the idea of moments and
bounding volumes to construct a derived I-space for the probabilistic
case. This could yield the guaranteed correctness of plans while
also taking probabilities into account. Unfortunately, this would
once again increase the dimension of the derived I-space.
of the probability mass falls. In
general, it may be possible to combine the idea of moments and
bounding volumes to construct a derived I-space for the probabilistic
case. This could yield the guaranteed correctness of plans while
also taking probabilities into account. Unfortunately, this would
once again increase the dimension of the derived I-space.
Steven M LaValle 2012-04-20