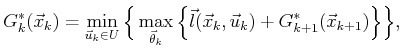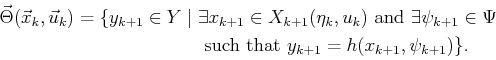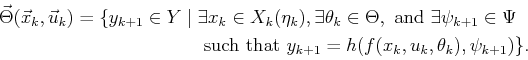Next: Policy iteration Up: 12.1.2 Algorithms for Nondeterministic Previous: 12.1.2 Algorithms for Nondeterministic
The value-iteration method from Section 10.2.1 can be
applied without modification. In the first step, initialize
![]() using (12.6). Using the notation for the new
problem, the dynamic programming recurrence, (10.39),
becomes
using (12.6). Using the notation for the new
problem, the dynamic programming recurrence, (10.39),
becomes
The main difficulty in evaluating (12.7) is to
determine the set
![]() , over which the
maximization occurs. Suppose that a state-nature sensor mapping is
used, as defined in Section 11.1.1. From the I-state
, over which the
maximization occurs. Suppose that a state-nature sensor mapping is
used, as defined in Section 11.1.1. From the I-state
![]() , the action
, the action
![]() is applied. This
yields a forward projection
is applied. This
yields a forward projection
![]() . The set of all
possible observations is
. The set of all
possible observations is
Steven M LaValle 2012-04-20