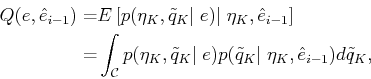Next: 12.4 Visibility-Based Pursuit-Evasion Up: 12.3.5 Probabilistic Localization and Previous: 12.3.5 Probabilistic Localization and
The problem is often solved in practice by applying the expectation-maximization (EM) algorithm [106]. In the general framework, there are three different spaces:
The EM algorithm involves an expectation step followed by a maximization step. The two steps are repeated as necessary until a solution with the desired accuracy is obtained. The method is guaranteed to converge under general conditions [269,977,978]. In practice, it appears to work well even under cases that are not theoretically guaranteed to converge [940].
From this point onward, let ![]() ,
,
![]() , and
, and ![]() denote the three
spaces for the EM algorithm because they pertain directly to the
problem. Suppose that a robot has moved in the environment for
denote the three
spaces for the EM algorithm because they pertain directly to the
problem. Suppose that a robot has moved in the environment for ![]() stages, resulting in a final stage,
stages, resulting in a final stage, ![]() . At each stage,
. At each stage,
![]() , an observation,
, an observation, ![]() , is made using its sensor.
This could, for example, represent a set of distance measurements made
by sonars or a range scanner. Furthermore, an action,
, is made using its sensor.
This could, for example, represent a set of distance measurements made
by sonars or a range scanner. Furthermore, an action, ![]() , is
applied for
, is
applied for ![]() to
to ![]() . A prior probability density function,
. A prior probability density function,
![]() , is initially assumed over
, is initially assumed over ![]() . This leads to the history
I-state,
. This leads to the history
I-state, ![]() , as defined in (11.14).
, as defined in (11.14).
Now imagine that ![]() stages have been executed, and the task is to
estimate
stages have been executed, and the task is to
estimate ![]() . From each
. From each ![]() , a measurement,
, a measurement, ![]() , of part of the
environment is taken. The EM algorithm generates a sequence of
improved estimates of
, of part of the
environment is taken. The EM algorithm generates a sequence of
improved estimates of ![]() . In each execution of the two EM steps, a
new estimate of
. In each execution of the two EM steps, a
new estimate of ![]() is produced. Let
is produced. Let ![]() denote this
estimate after the
denote this
estimate after the ![]() th iteration. Let
th iteration. Let
![]() denote the
configuration history from stage
denote the
configuration history from stage ![]() to stage
to stage ![]() . The expectation
step computes the expected likelihood of
. The expectation
step computes the expected likelihood of ![]() given
given ![]() .
This can be expressed as12.3
.
This can be expressed as12.3
| (12.31) |
Note that once determined, (12.30) is a function only of ![]() and
and
![]() . The maximization step involves selecting an
. The maximization step involves selecting an
![]() that minimizes (12.30):
that minimizes (12.30):
| (12.32) |
One important factor in the success of the method is in the
representation of ![]() . In the EM computations, one common approach is
to use a set of landmarks, which were mentioned in Section
11.5.1. These are special places in the environment that
can be identified by sensors, and if correctly classified, they
dramatically improve localization. In [941], the
landmarks are indicated by a user as the robot travels.
Classification and positioning errors can both be modeled
probabilistically and incorporated into the EM approach. Another idea
that dramatically simplifies the representation of
. In the EM computations, one common approach is
to use a set of landmarks, which were mentioned in Section
11.5.1. These are special places in the environment that
can be identified by sensors, and if correctly classified, they
dramatically improve localization. In [941], the
landmarks are indicated by a user as the robot travels.
Classification and positioning errors can both be modeled
probabilistically and incorporated into the EM approach. Another idea
that dramatically simplifies the representation of ![]() is to
approximate environments with a fine-resolution grid. Probabilities
are associated with grid cells, which leads to a data structure called
an occupancy grid [307,685,850]. In any case,
is to
approximate environments with a fine-resolution grid. Probabilities
are associated with grid cells, which leads to a data structure called
an occupancy grid [307,685,850]. In any case,
![]() must be carefully defined to ensure that reasonable prior
distributions can be made for
must be carefully defined to ensure that reasonable prior
distributions can be made for ![]() to initialize the EM algorithm as
the robot first moves.
to initialize the EM algorithm as
the robot first moves.
Steven M LaValle 2012-04-20