
Next: 14.6.3.5 A bang-bang approach Up: 14.6.3 Path-Constrained Trajectory Planning Previous: 14.6.3.3 The path-constrained phase
Dynamic programming with interpolation, as covered in Section
14.5, can be applied to solve the problem once it is
formulated in terms of the path-constrained phase space
![]() . The domain of
. The domain of ![]() provides the constraint
provides the constraint
![]() . Assume that only forward progress along the path is
needed; moving in the reverse direction should not be necessary. This
implies that
. Assume that only forward progress along the path is
needed; moving in the reverse direction should not be necessary. This
implies that
![]() . To make
. To make ![]() bounded, an upper bound,
bounded, an upper bound,
![]() , is usually assumed, beyond which it is known that the
speed is too high to follow the path.
, is usually assumed, beyond which it is known that the
speed is too high to follow the path.
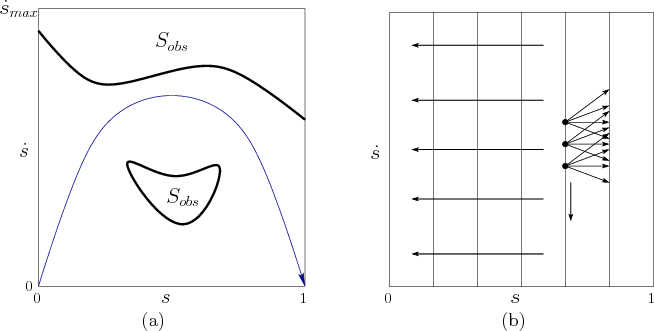 |
This results in the planning problem shown in Figure
14.27a. The system is expressed as
![]() , in
which
, in
which
![]() . The initial phase in
. The initial phase in ![]() is
is
![]() and the goal phase is
and the goal phase is
![]() . Typically,
. Typically,
![]() . The region shown in Figure
14.27 is contained in the first quadrant of the phase
space because only positive values of
. The region shown in Figure
14.27 is contained in the first quadrant of the phase
space because only positive values of ![]() and
and ![]() are allowed (in
Figure 14.13,
are allowed (in
Figure 14.13, ![]() and
and ![]() could be positive or
negative). This implies that all motions are to the right. The
actions determine whether accelerations or decelerations will occur.
could be positive or
negative). This implies that all motions are to the right. The
actions determine whether accelerations or decelerations will occur.
Backward value iteration with interpolation can be easily applied by
discretizing ![]() and
and
![]() . Due to the constraint
. Due to the constraint
![]() , making a Dijkstra-like
version of the algorithm is straightforward. A simple wavefront
propagation can even be performed, starting at
, making a Dijkstra-like
version of the algorithm is straightforward. A simple wavefront
propagation can even be performed, starting at ![]() and progressing
backward in vertical waves until
and progressing
backward in vertical waves until ![]() is reached. See Figure
14.27b. The backprojection
(14.29) can be greatly simplified. Suppose that the
is reached. See Figure
14.27b. The backprojection
(14.29) can be greatly simplified. Suppose that the
![]() -axis is discretized into
-axis is discretized into ![]() regularly spaced values
regularly spaced values ![]() ,
,
![]() ,
, ![]() at every
at every ![]() , for some fixed
, for some fixed
![]() .
Thus,
.
Thus,
![]() . The index
. The index ![]() can be interpreted as
the stage. Starting at
can be interpreted as
the stage. Starting at ![]() , the final cost-to-go
, the final cost-to-go
![]() is defined as 0 if the corresponding phase
represents the goal, and
is defined as 0 if the corresponding phase
represents the goal, and ![]() otherwise. At each
otherwise. At each ![]() , the
, the
![]() values are sampled, and the cost-to-go function is represented
using one-dimensional linear interpolation along the vertical axis.
At each stage, the dynamic programming computation
values are sampled, and the cost-to-go function is represented
using one-dimensional linear interpolation along the vertical axis.
At each stage, the dynamic programming computation
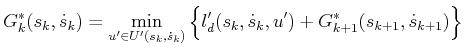 |
(14.46) |
The dynamic programming approach is so general that it can even be
extended to path-constrained trajectory planning in the presence of
higher order constraints [880]. For example, if a system is
specified as
![]() , then a 3D
path-constrained phase space results, in which each element is
expressed as
, then a 3D
path-constrained phase space results, in which each element is
expressed as
![]() . The actions in this space are
jerks, yielding
. The actions in this space are
jerks, yielding
![]() for
for
![]() .
.
Steven M LaValle 2012-04-20