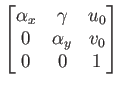Next: Laser-based implementation Up: 9.3 Tracking Position and Previous: The Perspective-n-Point (PnP) problem Contents Index
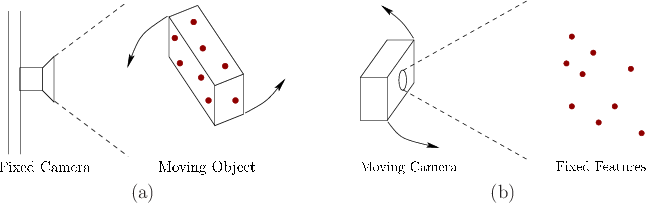
The visibility problem may be solved using a camera in two general ways, as indicated in Figure 9.15. Consider the camera frame, which is analogous to the eye frame from Figure 3.14 in Chapter 3. A world-fixed camera is usually stationary, meaning that the camera frame does not move relative to the world. A single transformation may be used to convert an object pose as estimated from the camera frame into a convenient world frame. For example, in the case of the Oculus Rift headset, the head pose could be converted to a world frame in which the ![]() direction is pointing at the camera,
direction is pointing at the camera, ![]() is ``up'', and the position is in the center of the camera's tracking region or a suitable default based on the user's initial head position. For an object-fixed camera, the estimated pose, derived from features that remain fixed in the world, is the transformation from the camera frame to the world frame. This case would be obtained, for example, if QR codes were placed on the walls.
is ``up'', and the position is in the center of the camera's tracking region or a suitable default based on the user's initial head position. For an object-fixed camera, the estimated pose, derived from features that remain fixed in the world, is the transformation from the camera frame to the world frame. This case would be obtained, for example, if QR codes were placed on the walls.
As in the case of an IMU, calibration is important for improving sensing accuracy. The following homogeneous transformation matrix can be applied to the image produced by a camera:
Now suppose that a feature has been observed in the image, perhaps using some form of blob detection to extract the pixels that correspond to it from the rest of the image [285,323]. This is easiest for a global shutter camera because all pixels will correspond to the same instant of time. In the case of a rolling shutter, the image may need to be transformed to undo the effects of motion (recall Figure 4.33). The location of the observed feature is calculated as a statistic of the blob pixel locations. Most commonly, the average over all blob pixels is used, resulting in non-integer image coordinates. Many issues affect performance: 1) quantization errors arise due to image coordinates for each blob pixel being integers; 2) if the feature does not cover enough pixels, then the quantization errors are worse; 3) changes in lighting conditions may make it difficult to extract the feature, especially in the case of natural features; 4) at some angles, two or more features may become close in the image, making it difficult to separate their corresponding blobs; 5) as various features enter or leave the camera view, the resulting estimated pose may jump. Furthermore, errors tend to be larger along the direction of the optical axis.
Steven M LaValle 2020-01-06