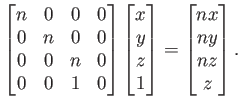Next: Keeping track of depth Up: 3.5 Chaining the Transformations Previous: 3.5 Chaining the Transformations Contents Index
The next transformation, ![]() performs the perspective projection as described in Section 3.4; however, we must explain how it is unnaturally forced into a 4 by 4 matrix. We also want the result to be in a canonical form that appears to be unitless, which is again motivated by industrial needs. Therefore,
performs the perspective projection as described in Section 3.4; however, we must explain how it is unnaturally forced into a 4 by 4 matrix. We also want the result to be in a canonical form that appears to be unitless, which is again motivated by industrial needs. Therefore, ![]() is called the canonical view transform. Figure 3.18 shows a viewing frustum, which is based on the four corners of a rectangular virtual screen. At
is called the canonical view transform. Figure 3.18 shows a viewing frustum, which is based on the four corners of a rectangular virtual screen. At ![]() and
and ![]() lie a near plane and far plane, respectively. Note that
lie a near plane and far plane, respectively. Note that ![]() for these cases because the
for these cases because the ![]() axis points in the opposite direction. The virtual screen is contained in the near plane. The perspective projection should place all of the points inside of the frustum onto a virtual screen that is centered in the near plane. This implies
axis points in the opposite direction. The virtual screen is contained in the near plane. The perspective projection should place all of the points inside of the frustum onto a virtual screen that is centered in the near plane. This implies ![]() using (3.40).
using (3.40).
We now want to reproduce (3.40) using a matrix. Consider the result of applying the following matrix multiplication:
| (3.43) |
| (3.44) |
Steven M LaValle 2020-01-06