 Build larger
RRT -->
Build larger
RRT --> 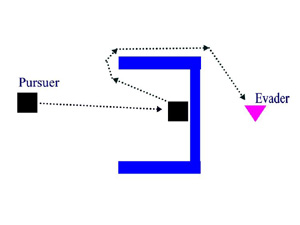
by Jason Stanek and Matthew Marks
May 7, 2000
Project Description
Project Focus
The project focuses on an pseudo algorithm for a 2D Pursuer robot that attempts to reach a mobile Goal Position. The Pursuer exists in a 2D world with translating and rotating objects, where the paths of all obstacles are predictable. The initial location of the Goal Position is determined by the user of the program, and can be constantly moved. Since the goal is a location, it can exist anywhere in the C-space, including inside the bounds of obstacles.
Both the Pursuer and Goal Position move at equal, pre-defined distances, per each increment of time.
The desired effect of the application is that the Pursuer is able to
reach the Goal Position in any 2D environment that is solvable. The
Goal Position is arrived at by using a combination of RRTs, Anticipation
of the Goal Position's movements, and near-sighted, line-of-sight
movements.
The Pursuer has complete knowledge of all objects in the world and the
location of the Goal Position.
Critical Events
Since the Goal Position can be stationary or moving, we decided
continuously
build small RRTs until the Goal Position is reached, as opposed to creating
one large RRT that lead from the initial position of the Pursuer to the
Goal Position. The reasoning for this was, by the time the Pursuer
traveled a branch of the RRT, all the way to the position where the Goal
Position had initially been, it is highly possible that the Goal Position
will have moved. The path towards a moving Goal Position has tended
to be more accurate by using a series of smaller RRT's that don't cover
a large amount of Cfree, but enough area is covered to move
the Pursuer robot in the general location of its goal. What this
calls for is a dynamic RRT. For this purpose, we built an RRT limited
in size and biased toward the Goal Position. This smaller RRT provides
near-sighted knowledge of
how to begin moving toward the Goal Position. After a few moves,
the branches on the RRT that the robot did not travel on are recycled and
used to extend the current branch further toward the Goal Position.
This method, alone, tends to work well for worlds where the paths to the
Goal Position are straight-forward with obstacles that do not trap the
Pursuer.
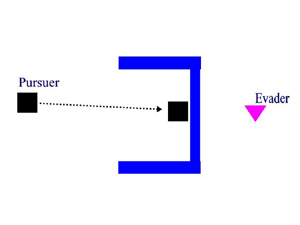
If the Pursuer is in a world where the Pursuer can get stuck among
obstacles,
such that it can not get any closer to the Goal Position by recreating
the small RRT, then the Pursuer changes tactics. Instead of making
an RRT of limited size, the Pursuer begins to add additional nodes to the
RRT with the intention of covering as much of the world as necessary until
it finds a path that is closer to the Goal Position. This technique tends
to help push the Pursuer out of a position that a limited-in-size RRT can
not do, as might happen in a non convex polygon. The following images
display an example of when the creation of a larger RRT would be
necessary.
Also, the Computed Example, Sample 1, gives a running example of this tactic.
Build larger
RRT -->
These two tactics of the Pursuer enable it to reach the Goal Position very consistently. There are additional features of the algorithm which improves its ability to "catch" the Goal Position which will be detailed below, but the above is what is essential.
The Pursuer has a modest calculation for anticipating the Goal Position's
movements. The Pursuer keeps track of the general direction the Goal
Position has been traveling in, and plots where the Goal Position will
be if it continues in the same direction.
This anticipated position is what the RRT is biased toward, when the
Pursuer robot is a significant distance away from the Goal Position.
As the Pursuer gets closer to the Goal Position, the RRT changes to be
biased toward the actual point of the Goal Position.
Now there can be a conflict between the anticipation of the location of the Goal Position, and the tactic of the RRT expanding throughout Cfree when the Pursuer can not get closer to the Goal Position. The reason for this conflict is as follows: If, as in the two images above, the Pursuer gets caught in an obstacle and can not move closer to the Goal Position, it expands its RRT. However, if the Goal Position was to move up and down slightly, then the Pursuer would always be able to move closer to the Goal Position by small increments, without ever getting out of the obstacle. And so, the Pursuer would never reach the Goal Position.
To avoid this conflict, a record of the location of the Goal Position
is maintained. Then, before the Pursuer builds its biased RRT, a
calculation is done to determine if the past movements of the Goal Position
have moved a significant amount, or if all of the Goal Position's movements
have kept it in the same local area. --TO BE
CONTINUED--
Because of this anticipation method, the Goal Position could try to
trick the Pursuer by quickly moving back and forth
rapidly. This would cause the Pursuer difficulty in getting closer
to the Goal Position, if the Pursuer is far away. To avoid this,
the Pursuer tries to get closer to the general area that the Goal Position
is in, or predicted to be until it is very close to the Goal Position.
The area that the Goal Position is in includes the Goal Position with a
general radius of R. This means that if the Goal Position is at some
position P1, and moves to position P2 that is beyond the radius R, the
Goal Position is considered to have moved. But if P2 is less than
R distance from P1, the Goal Position has essentially remained still.
Therefore, it is not as easy for the Goal Position to confuse the Pursuer
when it attempts to anticipate where the Goal Position is moving to, or
just staying in the same area.
Algorithm Components
The Stanek Marks Anticipating Rapidly Exploring
Random Tree
( The SMARRT Algorithm )
Track_Evader( )
Initialize_RRT( small_number_of_nodes );
While ( Pursuer has not captured the Evader )
If ( Pursuer is very close to Evader and line-of-sight )
Move_Directly_Toward_Evader (. );
Else
If ( Pursuer can get closer to the predicted area Evader will be in
)
Move_Pursuer_Closer( );
Build_New_RRT ( );
Else //Can not get any closer.
Add_Nodes_2_RRT( );
While (Pursuer is not any closer to the Evader )
Add_Nodes_2_RRT( );
While ( not (Number_Nodes_In_RRT equal
small_number_of_nodes)
)
Move_Pursuer_Closer( );
Remove_Nodes_From_RRT_That_Are_Behind_Pursuer ( );
End Track_Evader.
Algorithm analysis
The Stanek Marks Anticipating Rapidly Exploring
Random Tree
( The SMARRT Algorithm )
What may be implemented next?
Sample 2.
Sample 3.
Sample 4.
Source Code:
With props to grif