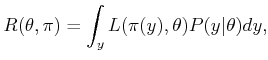Next: 9.5.2.2 The source of Up: 9.5.2 Concerns Regarding the Previous: 9.5.2 Concerns Regarding the
For the past century and a half, there has been a fundamental debate among statisticians on the meaning of probabilities. Virtually everyone is satisfied with the axioms of probability, but beyond this, what is their meaning when making inferences? The two main camps are the frequentists and the Bayesians. A form of Bayes' rule was published in 1763 after the death of Bayes [80]. During most of the nineteenth century Bayesian analysis tended to dominate literature; however, during the twentieth century, the frequentist philosophy became more popular as a more rigorous interpretation of probabilities. In recent years, the credibility of Bayesian methods has been on the rise again.
As seen so far, a Bayesian interprets probabilities as the degree of belief in a hypothesis. Under this philosophy, it is perfectly valid to begin with a prior distribution, gather a few observations, and then make decisions based on the resulting posterior distribution from applying Bayes' rule.
From a frequentist perspective, Bayesian analysis makes far too
liberal use of probabilities. The frequentist believes that
probabilities are only defined as the quantities obtained in the limit
after the number of independent trials tends to infinity. For
example, if an unbiased coin is tossed over numerous trials, the
probability ![]() represents the value to which the ratio between
heads and the total number of trials will converge as the number of
trials tends to infinity. On the other hand, a Bayesian might say
that the probability that the next trial results in heads is
represents the value to which the ratio between
heads and the total number of trials will converge as the number of
trials tends to infinity. On the other hand, a Bayesian might say
that the probability that the next trial results in heads is
![]() . To a frequentist, this interpretation of probability is too
strong.
. To a frequentist, this interpretation of probability is too
strong.
Frequentists have developed a version of decision theory based on their philosophy; comparisons between the two appear in [831]. As an example, a frequentist would advocate optimizing the following frequentist risk to obtain a decision rule:
Steven M LaValle 2012-04-20