
Next: 10.2 Algorithms for Computing Up: 10.1.3 A Plan and Previous: Graph representations of a
Consider the cost-to-go of executing a plan ![]() from a state
from a state
![]() . The resulting cost depends on the sequences of states
that are visited, actions that are applied by the plan, and the
applied nature actions. In Chapter 2 this was
obtained by adding the cost terms, but now there is a dependency on
nature. Both worst-case and expected-case analyses are possible,
which generalize the treatment of Section 9.2 to state
spaces and multiple stages.
. The resulting cost depends on the sequences of states
that are visited, actions that are applied by the plan, and the
applied nature actions. In Chapter 2 this was
obtained by adding the cost terms, but now there is a dependency on
nature. Both worst-case and expected-case analyses are possible,
which generalize the treatment of Section 9.2 to state
spaces and multiple stages.
Let
![]() denote the set of state-action-nature
histories that could arise from
denote the set of state-action-nature
histories that could arise from ![]() when applied using
when applied using ![]() as
the initial state. The cost-to-go,
as
the initial state. The cost-to-go,
![]() , under a given
plan
, under a given
plan ![]() from
from ![]() can be measured using worst-case
analysis as
can be measured using worst-case
analysis as
An optimal plan using worst-case analysis is any plan for which
![]() is minimized over all possible plans (all ways to
assign actions to the states). In the case of feasible planning,
there are usually numerous equivalent alternatives. Sometimes the
task may be only to find a feasible plan, which means that all
trajectories must reach the goal, but the cost does not need to be
optimized.
is minimized over all possible plans (all ways to
assign actions to the states). In the case of feasible planning,
there are usually numerous equivalent alternatives. Sometimes the
task may be only to find a feasible plan, which means that all
trajectories must reach the goal, but the cost does not need to be
optimized.
Using probabilistic uncertainty, the cost of a plan can be measured using expected-case analysis as
An interesting question now emerges: Can the same plan, ![]() , be
optimal from every initial state
, be
optimal from every initial state ![]() , or do we need to
potentially find a different optimal plan for each initial state?
Fortunately, a single plan will suffice to be optimal over all initial
states. Why? This behavior was also observed in Section
8.2.1. If
, or do we need to
potentially find a different optimal plan for each initial state?
Fortunately, a single plan will suffice to be optimal over all initial
states. Why? This behavior was also observed in Section
8.2.1. If ![]() is optimal from some
is optimal from some ![]() , then it
must also be optimal from every other state that is potentially
visited by executing
, then it
must also be optimal from every other state that is potentially
visited by executing ![]() from
from ![]() . Let
. Let ![]() denote some visited
state. If
denote some visited
state. If ![]() was not optimal from
was not optimal from ![]() , then a better plan would
exist, and the goal could be reached from
, then a better plan would
exist, and the goal could be reached from ![]() with lower cost. This
contradicts the optimality of
with lower cost. This
contradicts the optimality of ![]() because solutions must travel
through
because solutions must travel
through ![]() . Let
. Let ![]() denote a plan that is optimal from every
initial state.
denote a plan that is optimal from every
initial state.
Steven M LaValle 2012-04-20
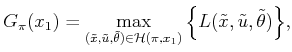
![$\displaystyle G_\pi (x_1) = E_{{\cal H}(\pi ,x_1)} \Big[ L({\tilde{x}},{\tilde{u}},{\tilde{\theta}}) \Big],$](img4043.gif)