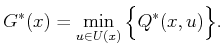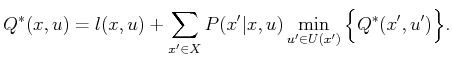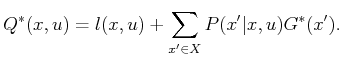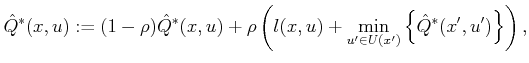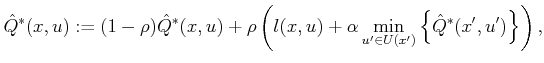Next: Policy iteration Up: 10.4.3 Q-Learning: Computing an Previous: 10.4.3 Q-Learning: Computing an
A simulation-based version of value iteration can be constructed from
Q-factors. The reason for their use instead of ![]() is that a
minimization over
is that a
minimization over ![]() will be avoided in the dynamic programming.
Avoiding this minimization enables a sample-by-sample approach to
estimating the optimal values and ultimately obtaining the optimal
plan. The optimal cost-to-go can be obtained from the Q-factors as
will be avoided in the dynamic programming.
Avoiding this minimization enables a sample-by-sample approach to
estimating the optimal values and ultimately obtaining the optimal
plan. The optimal cost-to-go can be obtained from the Q-factors as
If
![]() and
and ![]() were known, then (10.98)
would lead to an alternative, storage-intensive way to perform value
iteration. After convergence occurs, (10.97) can be used to
obtain the
were known, then (10.98)
would lead to an alternative, storage-intensive way to perform value
iteration. After convergence occurs, (10.97) can be used to
obtain the ![]() values. The optimal plan is constructed as
values. The optimal plan is constructed as
Since the costs and transition probabilities are unknown, a
simulation-based approach is needed. The stochastic iterative
algorithm idea can be applied once again. Recall that
(10.96) estimated the cost of a plan by using individual
samples and required a convergence-rate parameter, ![]() . Using the
same idea here, a simulation-based version of value iteration can be
derived as
. Using the
same idea here, a simulation-based version of value iteration can be
derived as
In most literature, Q-learning is applied to the discounted cost model. This yields a minor variant of (10.101):