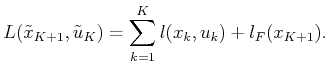Next: The cost of a Up: 11.1 Discrete State Spaces Previous: The history information space
Planning problems will be defined directly on the history I-space, which makes it appear as an ordinary state space in many ways. Keep in mind, however, that it was derived from another state space for which perfect state observations could not be obtained. In Section 10.1, a feedback plan was defined as a function of the state. Here, a feedback plan is instead a function of the I-state. Decisions cannot be based on the state because it will be generally unknown during the execution of the plan. However, the I-state is always known; thus, it is logical to base decisions on it.
Let ![]() denote a
denote a ![]() -step information-feedback plan,
which is a sequence
-step information-feedback plan,
which is a sequence ![]() ,
, ![]() ,
, ![]() ,
, ![]() ) of
) of
![]() functions,
functions,
![]() . Thus, at every stage
. Thus, at every stage
![]() , the I-state
, the I-state
![]() is used as a basis for choosing
the action
is used as a basis for choosing
the action
![]() . Due to interference of nature
through both the state transition equation and the sensor mapping, the
action sequence
. Due to interference of nature
through both the state transition equation and the sensor mapping, the
action sequence
![]() produced by a plan,
produced by a plan, ![]() ,
will not be known until the plan terminates.
,
will not be known until the plan terminates.
As in Formulation 2.3, it will be convenient to assume that
![]() contains a termination action,
contains a termination action, ![]() . If
. If ![]() is applied
at stage
is applied
at stage ![]() , then it is repeatedly applied forever. It is assumed
once again that the state
, then it is repeatedly applied forever. It is assumed
once again that the state ![]() remains fixed after the termination
condition is applied. Remember, however,
remains fixed after the termination
condition is applied. Remember, however, ![]() is still unknown in
general; it becomes fixed but unknown. Technically, based on the
definition of the history I-space, the I-state must change after
is still unknown in
general; it becomes fixed but unknown. Technically, based on the
definition of the history I-space, the I-state must change after ![]() is applied because the history grows. These changes can be ignored,
however, because no new decisions are made after
is applied because the history grows. These changes can be ignored,
however, because no new decisions are made after ![]() is applied. A
plan that uses a termination condition can be specified as
is applied. A
plan that uses a termination condition can be specified as
![]() because the number of stages may vary each
time the plan is executed. Using the history I-space definition in
(11.19), an information-feedback plan is expressed
as
because the number of stages may vary each
time the plan is executed. Using the history I-space definition in
(11.19), an information-feedback plan is expressed
as
Some immediate extensions of Formulation 11.1 are possible,
but we avoid them here simplify notation in the coming concepts. One
extension is to allow different action sets, ![]() , for each
, for each ![]() . Be careful, however, because information regarding the current
state can be inferred if the action set
. Be careful, however, because information regarding the current
state can be inferred if the action set ![]() is given, and it varies
depending on
is given, and it varies
depending on ![]() . Another extension is to allow the costs to depend
on nature, to obtain
. Another extension is to allow the costs to depend
on nature, to obtain
![]() , instead of
, instead of
![]() in
(11.21).
in
(11.21).