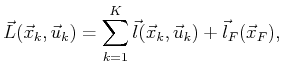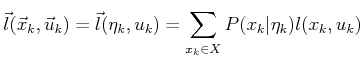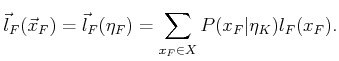Next: 12.1.2 Algorithms for Nondeterministic Up: 12.1 General Methods Previous: 12.1 General Methods
Recall that any problem specified using Formulation 11.1 can be converted using derived I-states into a problem under Formulation 10.1. By building on the discussion from the end of Section 11.1.3, this can be achieved by treating the I-space as a big state space in which each state is an I-state in the original problem formulation. Some of the components were given previously, but here a complete formulation is given.
Suppose that a problem has been specified using Formulation
11.1, resulting in the usual components: ![]() ,
, ![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() . The following concepts will
work for any sufficient I-map; however, the presentation will be
limited to two important cases:
. The following concepts will
work for any sufficient I-map; however, the presentation will be
limited to two important cases:
![]() and
and
![]() , which
yield derived I-spaces
, which
yield derived I-spaces
![]() and
and
![]() , respectively (recall
Sections 11.2.2 and 11.2.3).
, respectively (recall
Sections 11.2.2 and 11.2.3).
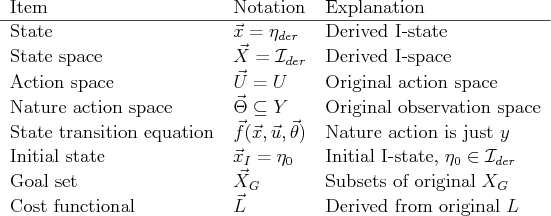 |
The components of Formulation 10.1 will now be specified
using components of the original problem. To avoid confusion between
the two formulations, an arrow will be placed above all components of
the new formulation. Figure 12.1 summarizes the coming
definitions. The new state space, ![]() , is defined as
, is defined as
![]() , and a state,
, and a state,
![]() , is a derived I-state,
, is a derived I-state,
![]() . Under nondeterministic uncertainty,
. Under nondeterministic uncertainty,
![]() means
means
![]() , in which
, in which ![]() is the history I-state. Under
probabilistic uncertainty,
is the history I-state. Under
probabilistic uncertainty,
![]() means
means
![]() . The
action space remains the same:
. The
action space remains the same:
![]() .
.
The strangest part of the formulation is the new nature action space,
![]() . The observations in Formulation
11.1 behave very much like nature actions because they are
not selected by the robot, and, as will be seen shortly, they are the
only unpredictable part of the new state transition equation.
Therefore,
. The observations in Formulation
11.1 behave very much like nature actions because they are
not selected by the robot, and, as will be seen shortly, they are the
only unpredictable part of the new state transition equation.
Therefore,
![]() , the original
observation space. A new nature action,
, the original
observation space. A new nature action,
![]() , is
just an observation,
, is
just an observation,
![]() . The set
. The set
![]() generally depends on
generally depends on ![]() and
and ![]() because some observations may be impossible to receive from some
states. For example, if a sensor that measures a mobile robot
position is never wrong by more than
because some observations may be impossible to receive from some
states. For example, if a sensor that measures a mobile robot
position is never wrong by more than ![]() meter, then observations that
are further than
meter, then observations that
are further than ![]() meter from the true robot position are
impossible.
meter from the true robot position are
impossible.
A derived state transition equation is defined with
![]() and yields a new state,
and yields a new state,
![]() . Using the original notation, this is just a function
that uses
. Using the original notation, this is just a function
that uses
![]() ,
, ![]() , and
, and ![]() to compute the next
derived I-state,
to compute the next
derived I-state,
![]() , which is allowed because we are
working with sufficient I-maps, as described in Section
11.2.1.
, which is allowed because we are
working with sufficient I-maps, as described in Section
11.2.1.
Initial states and goal sets are optional and can be easily
formulated in the new representation. The initial I-state, ![]() ,
becomes the new initial state,
,
becomes the new initial state,
![]() . It is assumed that
. It is assumed that
![]() is either a subset of
is either a subset of ![]() or a probability distribution,
depending on whether planning occurs in
or a probability distribution,
depending on whether planning occurs in
![]() or
or
![]() . In
the nondeterministic case, the new goal set
. In
the nondeterministic case, the new goal set
![]() can be derived
as
can be derived
as
| (12.1) |
The only remaining portion of Formulation 10.1 is the cost
functional. We will develop a cost model that uses only the state and
action histories. A dependency on nature would imply that the costs
depend directly on the observation,
![]() , which was not
assumed in Formulation 11.1. The general
, which was not
assumed in Formulation 11.1. The general ![]() -stage cost
functional from Formulation 10.1 appears in this context as
-stage cost
functional from Formulation 10.1 appears in this context as
The cost functional ![]() must be derived from the cost
functional
must be derived from the cost
functional ![]() of the original problem. This is expressed in terms
of states, which are unknown. First consider the case of
of the original problem. This is expressed in terms
of states, which are unknown. First consider the case of
![]() .
The state
.
The state ![]() at stage
at stage ![]() follows the probability distribution
follows the probability distribution
![]() , as derived in Section 11.2.3. Using
, as derived in Section 11.2.3. Using
![]() , an expected cost is assigned as
, an expected cost is assigned as
Ideally, we would like to make analogous expressions for the case of
![]() ; however, there is one problem. Formulating the worst-case
cost for each stage is too pessimistic. For example, it may be
possible to obtain high costs in two consecutive stages, but each of
these may correspond to following different paths in
; however, there is one problem. Formulating the worst-case
cost for each stage is too pessimistic. For example, it may be
possible to obtain high costs in two consecutive stages, but each of
these may correspond to following different paths in ![]() . There is
nothing to constrain the worst-case analysis to the same path.
In the probabilistic case there is no problem because probabilities
can be assigned to paths. For the nondeterministic case, a cost
functional can be defined, but the stage-additive property needed for
dynamic programming is destroyed in general. Under some restrictions
on allowable costs, the stage-additive property is preserved.
. There is
nothing to constrain the worst-case analysis to the same path.
In the probabilistic case there is no problem because probabilities
can be assigned to paths. For the nondeterministic case, a cost
functional can be defined, but the stage-additive property needed for
dynamic programming is destroyed in general. Under some restrictions
on allowable costs, the stage-additive property is preserved.
The state ![]() at stage
at stage ![]() is known to lie in
is known to lie in
![]() , as
derived in Section 11.2.2. For every history I-state,
, as
derived in Section 11.2.2. For every history I-state,
![]() , and
, and ![]() , assume that
, assume that
![]() is invariant
over all
is invariant
over all
![]() . In this case,
. In this case,
A plan on the derived I-space,
![]() or
or
![]() , can now also
be considered as a plan on the new state space
, can now also
be considered as a plan on the new state space ![]() . Thus, state
feedback is now possible, but in a larger state space
. Thus, state
feedback is now possible, but in a larger state space ![]() instead
of
instead
of ![]() . The outcomes of actions are still generally unpredictable due
to the observations. An interesting special case occurs when there
are no observations. In this case, the I-state is predictable because
it is derived only from actions that are chosen by the robot. In this
case, the new formulation does not need nature actions, which reduces
it down to Formulation 2.3. Due to this, feedback is no
longer needed if the initial I-state is given. A plan can be
expressed once again as a sequence of actions. Even though the original states are not predictable, the future information
states are! This means that the state trajectory in the new state
space is completely predictable as well.
. The outcomes of actions are still generally unpredictable due
to the observations. An interesting special case occurs when there
are no observations. In this case, the I-state is predictable because
it is derived only from actions that are chosen by the robot. In this
case, the new formulation does not need nature actions, which reduces
it down to Formulation 2.3. Due to this, feedback is no
longer needed if the initial I-state is given. A plan can be
expressed once again as a sequence of actions. Even though the original states are not predictable, the future information
states are! This means that the state trajectory in the new state
space is completely predictable as well.