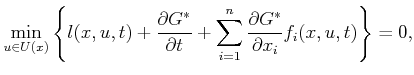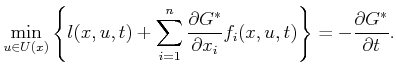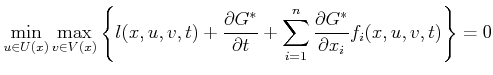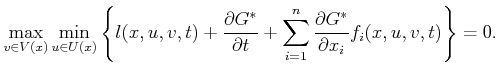Next: 15.2.2 Linear-Quadratic Problems Up: 15.2.1 Hamilton-Jacobi-Bellman Equation Previous: 15.2.1.2 The continuous case
Several versions of the HJB equation exist. The one presented in (15.14) is suitable for planning problems such as those expressed in Chapter 14. If the cost-to-go functions are time-dependent, then the HJB equation is
In differential game theory, the HJB equation generalizes to the Hamilton-Jacobi-Isaacs (HJI) equations [59,477]. Suppose that the system is given as
(13.203) and a zero-sum game is defined using a cost term
of the form
![]() . The HJI equations characterize saddle
equilibria and are given as
. The HJI equations characterize saddle
equilibria and are given as
Steven M LaValle 2012-04-20