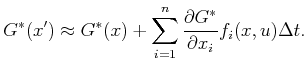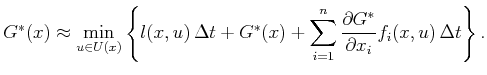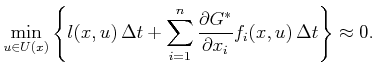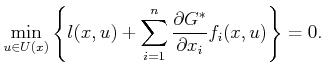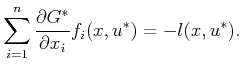Next: 15.2.1.3 Variants of the Up: 15.2.1 Hamilton-Jacobi-Bellman Equation Previous: 15.2.1.1 The discrete case
Now consider adapting to the continuous case. Suppose ![]() and
and ![]() are
both continuous, but discrete stages remain, and verify that
(15.5) to (15.8) still hold true. Their
present form can be used for any system that is approximated by
discrete stages. Suppose that the discrete-time model of Section
14.2.2 is used to approximate a system
are
both continuous, but discrete stages remain, and verify that
(15.5) to (15.8) still hold true. Their
present form can be used for any system that is approximated by
discrete stages. Suppose that the discrete-time model of Section
14.2.2 is used to approximate a system
![]() on
a state space
on
a state space ![]() that is a smooth manifold. In that model,
that is a smooth manifold. In that model, ![]() was
discretized to
was
discretized to ![]() , but here it will be left in its original form.
Let
, but here it will be left in its original form.
Let ![]() represent the time discretization.
represent the time discretization.
The HJB equation will be obtained by approximating (15.6)
with the discrete-time model and letting ![]() approach zero.
The arguments here are very informal; see [95,570,912]
for more details. Using discrete-time approximation, the dynamic
programming recurrence is
approach zero.
The arguments here are very informal; see [95,570,912]
for more details. Using discrete-time approximation, the dynamic
programming recurrence is
Using the linear part of a Taylor series expansion about ![]() , the term
, the term
![]() can be approximated as
can be approximated as
Compare the HJB equation to (15.6) for the discrete-time
case. Both indicate how the cost changes when moving in the best
direction. Substitution of ![]() for the optimal action into
(15.14) yields
for the optimal action into
(15.14) yields
The HJB equation, together with a boundary condition that specifies the final-stage cost, sufficiently characterizes the optimal solution to the planning problem. Since it is expressed over the whole state space, solutions to the HJB equation yield optimal feedback plans. Unfortunately, the HJB equation cannot be solved analytically in most settings. Therefore, numerical techniques, such as the value iteration method of Section 14.5, must be employed. There is, however, an important class of problems that can be directly solved using the HJB equation; see Section 15.2.2.
Steven M LaValle 2012-04-20