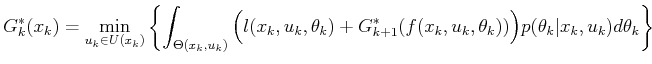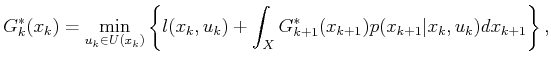Next: 10.6.2 Motion planning with Up: 10.6 Continuous State Spaces Previous: 10.6 Continuous State Spaces
The presentation follows in the same way as in Section
8.5.2, by beginning with the discrete problem and making
various components continuous. Begin with Formulation
10.1 and let ![]() be a bounded, open subset of
be a bounded, open subset of
![]() .
Assume that
.
Assume that ![]() and
and
![]() are finite. The value-iteration
methods of Section 10.2.1 can be directly applied by using
the interpolation concepts from Section 8.5.2 to compute
the cost-to-go values over
are finite. The value-iteration
methods of Section 10.2.1 can be directly applied by using
the interpolation concepts from Section 8.5.2 to compute
the cost-to-go values over ![]() . In the nondeterministic case,
the recurrence is (10.39), in which
. In the nondeterministic case,
the recurrence is (10.39), in which ![]() is
represented on a finite sample set
is
represented on a finite sample set
![]() and is evaluated on
all other points in
and is evaluated on
all other points in ![]() by interpolation (recall from Section
8.5.2 that
by interpolation (recall from Section
8.5.2 that ![]() is the interpolation
region of
is the interpolation
region of ![]() ). In
the probabilistic case, (10.45) or
(10.46) may once again be used, but
). In
the probabilistic case, (10.45) or
(10.46) may once again be used, but ![]() is
evaluated by interpolation.
is
evaluated by interpolation.
If ![]() is continuous, then it can be sampled to evaluate the
is continuous, then it can be sampled to evaluate the ![]() in each recurrence, as suggested in Section 8.5.2. Now
suppose
in each recurrence, as suggested in Section 8.5.2. Now
suppose
![]() is continuous. In the nondeterministic case,
is continuous. In the nondeterministic case,
![]() can be sampled to evaluate the
can be sampled to evaluate the ![]() in
(10.39) or it may be possible to employ a general
optimization technique directly over
in
(10.39) or it may be possible to employ a general
optimization technique directly over
![]() . In the
probabilistic case, the expectation must be taken over a continuous
probability space. A probability density function,
. In the
probabilistic case, the expectation must be taken over a continuous
probability space. A probability density function,
![]() ,
characterizes nature's action. A probabilistic state transition
density function can be derived from this as
,
characterizes nature's action. A probabilistic state transition
density function can be derived from this as
![]() .
Using these densities, the continuous versions of
(10.45) and (10.46) become
.
Using these densities, the continuous versions of
(10.45) and (10.46) become
Section 8.5.2 concluded by describing Dijkstra-like
algorithms for continuous spaces. These were derived mainly by using
backprojections, (8.66), to conclude that some samples
cannot change their values because they are too far from the active
set. The same principle can be applied in the current setting;
however, the weak backprojection,
(10.20), must be used instead. Using the weak
backprojection, the usual value iterations can be applied while
removing all samples that are not in the active set. For many
problems, however, the size of the active set may quickly become
unmanageable because the weak backprojection often causes much faster
propagation than the original backprojection. Continuous-state
generalizations of the Dijkstra-like algorithms in Section 10.2.3 can be made; however, this
requires the additional condition that in every iteration, it must be
possible to extend ![]() by forcing the next state to lie in
by forcing the next state to lie in ![]() , in
spite of nature.
, in
spite of nature.